
06 Sep Load Balancing in Distributed Systems
What is load balancing?
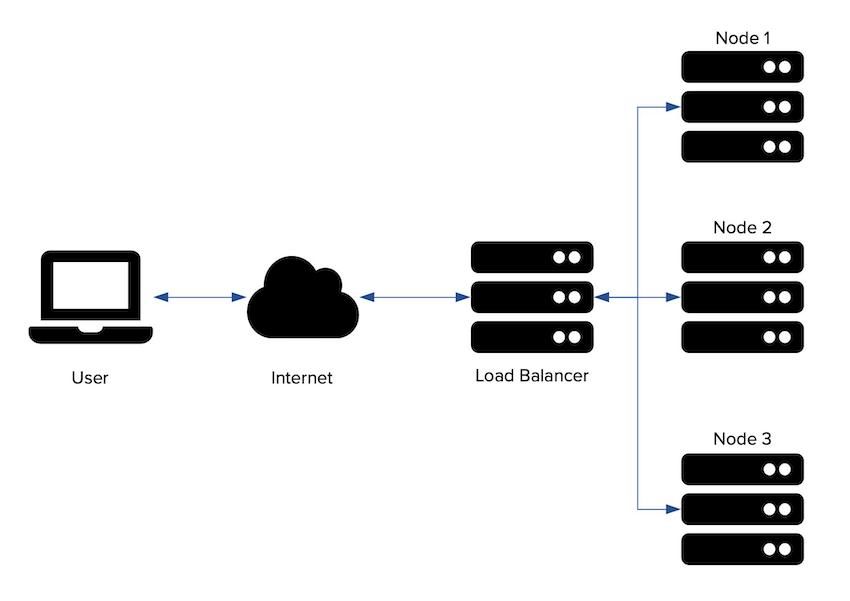
Load balancing is defined as the methodical and efficient distribution of requests across multiple servers. The load balancer sits between client devices and backend servers, receiving and then distributing incoming requests to a server that is healthy and capable of fulfilling them. A load balancer is a critical component of any distributed system as it helps improve the services offered by increasing availability and responsiveness. As it distributes the traffic across multiple servers, it also helps us avoid a single point of failure.
Why would I want to use a load balancer for my distributed system?
- First, it offers you an option to scale up your services. You do not have to worry about your standalone server as a single point of failure. You can actually distribute your requests now.
- It also offers redundancy, when the website traffic is sent to two or more web servers and one server fails, then the load balancer will automatically transfer the traffic to the other working servers.
Where can I put my load balancers?
Load balancers can sit in the architecture in three different levels:
- Between the client and the web server.
- Between the web server and the internal application server.
- Between the internal application layer and the database nodes.
Load Balancing Algorithms
How does a load balancer choose a server?
- It checks if the server is healthy. This essentially means that we just confirm if the server is up and running.
- It then selects an appropriate algorithm to select the server to which the request has to be redirected.
Some of the Load Balancing algorithms are:
- Least Connection Method — directs traffic to the server with the fewest active connections. Most useful when there are a large number of persistent connections in the traffic unevenly distributed between the servers.
- Least Response Time Method — directs traffic to the server with the fewest active connections and the lowest average response time.
- Round Robin Method — rotates servers by directing traffic to the first available server and then moves that server to the bottom of the queue. Most useful when servers are of equal specification and there are not many persistent connections.
- IP Hash — the IP address of the client determines which server receives the request.
No Comments