
16 Aug The CAP Theorem
Today’s technical architecture is inclined towards the distributed system because of the ease of scalability it provides. This scenario demands that we understand the trade-offs made in a distributed architecture, which brings us to the CAP theorem. Let’s begin right away but putting on our thinking caps!
Let us understand what each of these terms mean:
- Consistency: Consistency means that every server in the distributed architecture has the same data.
- Availability: If we say that a distributed system is available, it essentially means that every request that is received by the server is provided with a response. This response maybe a success or a failure message.
- Partition tolerance: Partition tolerance helps a distributed system avoid a single point of failure. The system continues to function even if a part of it is down.
Okay! This is great but how do we even achieve Consistency, Availability and Partition tolerance?
- Consistency is achieved when the data provided by each of the server is the same, i.e, consistent. Each of the server is updated with the data from other servers before a read is performed on it.
- Availability is guaranteed by replicating data across multiple servers.
- Partition tolerance is achieved by replicating the data across a combination of servers which helps us avoid a single point of failure or outage.
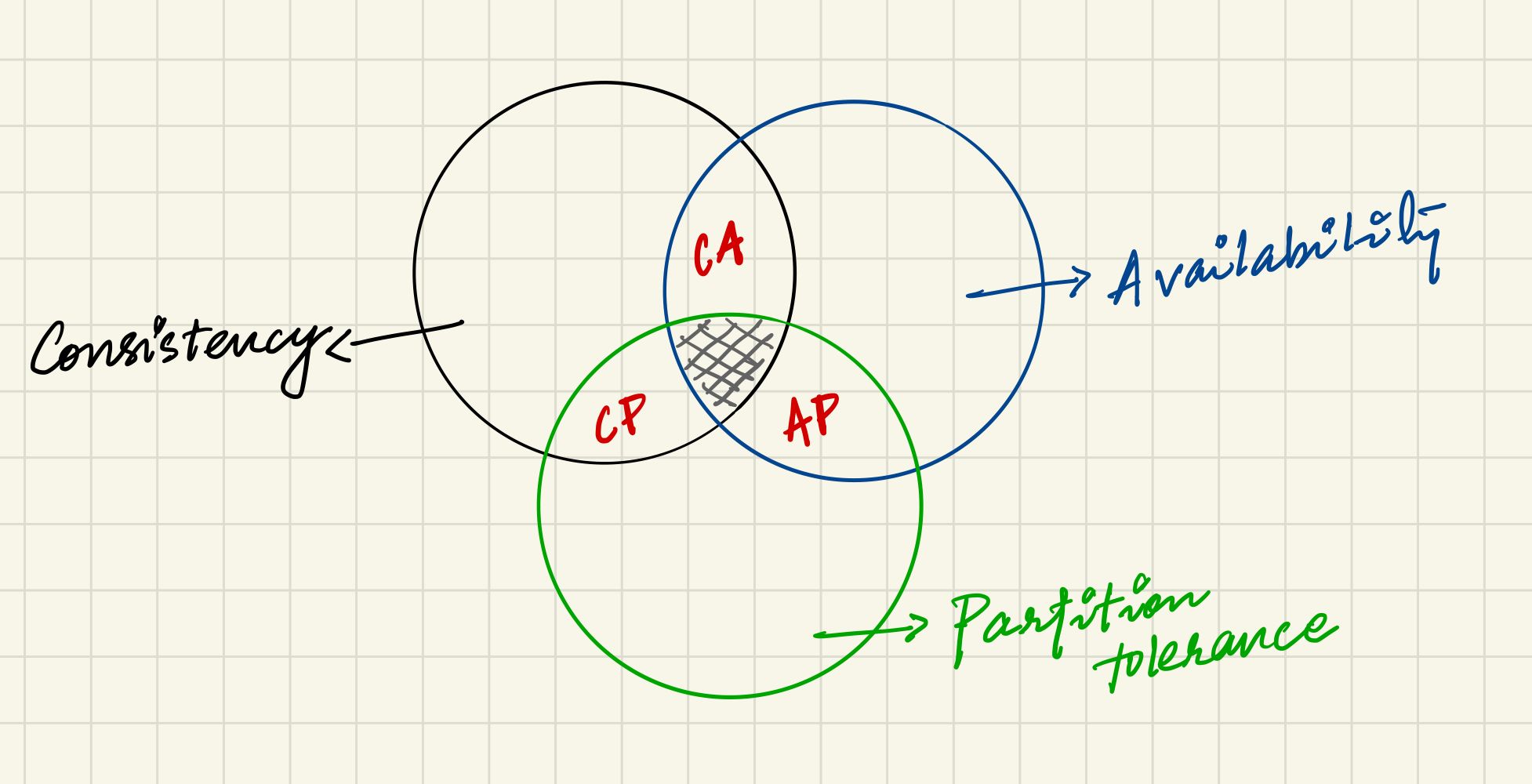
What does the CAP theorem actually say?
The CAP theorem suggests that only two of the three attributes (Consistency, availability and partition tolerance) are achievable in a distributed system. People often tend to misunderstand the CAP theorem. They think that the they need to abandon one of the attributes at all cost but this trade off between consistency and availability has to be made only when the network is down or unavailable.
For a distributed system to be consistent, all the servers should be able to see the updates in the same order. When the network happens to have a failure or downtime, these updates simply cannot be passed onto all the servers. We now have a system that is both consistent and also distributed. This makes it imperative for us to make our service unavailable so that we do not serve stale data as a response to the requests our servers receive.
Examples of systems that are:
- consistent and available: RDBMS
- available and have partition tolerance: DynamoDB
- consistent and have partition tolerance: MongoDB
That’ll be all folks! 😀
No Comments